Use Jupyter lab
A Powerful Workflow for Data Analysis and Visualization#
Though Deephaven has developed a powerful data interrogation (REPL / notebook) experience to support vital workflow, and to facilitate the launching of apps on the platform, our users also enjoy many additional capabilities and comfortable usage patterns by using Jupyter Notebook and Lab with Deephaven kernels.
In particular, the Deephaven-Python integration has focused on providing data scientists (and others similarly inclined) a smorgasbord of options:
- Delivering code to Deephaven from Jupyter — thereby using Deephaven as a server with Jupyter as a client.
- Supporting coding patterns that combine Python natively with Deephaven’s table operations.
- Integrating 2-way transformations between Pandas dataframes and Deephaven tables.
- Providing powerful multi-billion-row-eligible tables as widgets to Jupyter — complete with great user experiences for filtering, sorting, creating custom columns (from the table), etc.
- Support of Deephaven plotting widgets as a complement to Matplotlib and Seaborn. In particular, graphing large data sets is elegantly handled with these plotting widgets and their accompanying methods.
- Doing all of the above in such a way to support their application to real-time updating data sets and volumes that far exceed in-memory capacity.
Combining the power of the Deephaven Query Language and database with the familiar interface and vast capabilities of Jupyter yields software that can be more powerful than either of them alone.
Step-By-Step#
Before anything else, make sure you have access to the Deephaven IDE in your web browser of choice. This is to ensure that you are connected to an appropriate VPN and can identify the server you want to use. If you cannot access the Deephaven IDE, you will not be able to access the Deephaven servers from Jupyter.
Docker#
Docker provides a framework to deliver applications and their prerequisites in a pre-packaged unit. This allows use of complex applications without having to install and configure multiple products. In this context, Docker is used to deliver the Jupyter server and client components to be used with Deephaven. If you do not already have Docker, you can install it here.
(Note that Docker may need to be configured to point to the Docker repository containing the Deephaven images.)
note
See Deephaven Jupyter Notebooks for advanced instructions.
Launching Jupyter with Deephaven#
The Deephaven installation includes a Jupyter notebook start script which will automatically download from Docker hub (the default Docker repository) a Jupyter server image that is pre-configured to work with your Deephaven installation:
bash <(curl -Ss https://<DH SERVER URL AND PORT>/notebook/start.sh)
The server URL and port that you use to access a Deephaven system are the base URL and port that you will be using to access the web IDE, without the /iriside extension. After this executes successfully, it will run a Jupyter web server in the Docker image and produce the following URL’s to connect this server to your browser:

Now, you just copy and paste the second URL into your web browser of choice, and that’s it!
Upon this URL loading, you will be brought to Jupyter:
You can add your own folders for your own projects that will be stored in your local repository.
For example, I’ve added a folder for a COVID-19 project I’ve been working on:

If you navigate to the ‘examples’ folder, you will find a short Jupyter notebook containing some simple demonstrations of basic Deephaven functionality within Jupyter, such as calling a ticking dataset from a namespace and plotting an interactive table:

Using Speciality Libraries and Packages with Deephaven#
For the dataset displayed in the table above, we may want to produce a plot that shows the distribution of trading prices for a set of stocks in a given day. Deephaven has many native plots for working with time series data like line graphs, bar charts, and histograms. By working with Jupyter, we also have boundless Python plotting libraries at our fingertips. One of my personal favorites is seaborn, so I’ll use it to visualize the price distributions of Cisco, Intel, and Pfizer (these three because they’re relatively close in price):
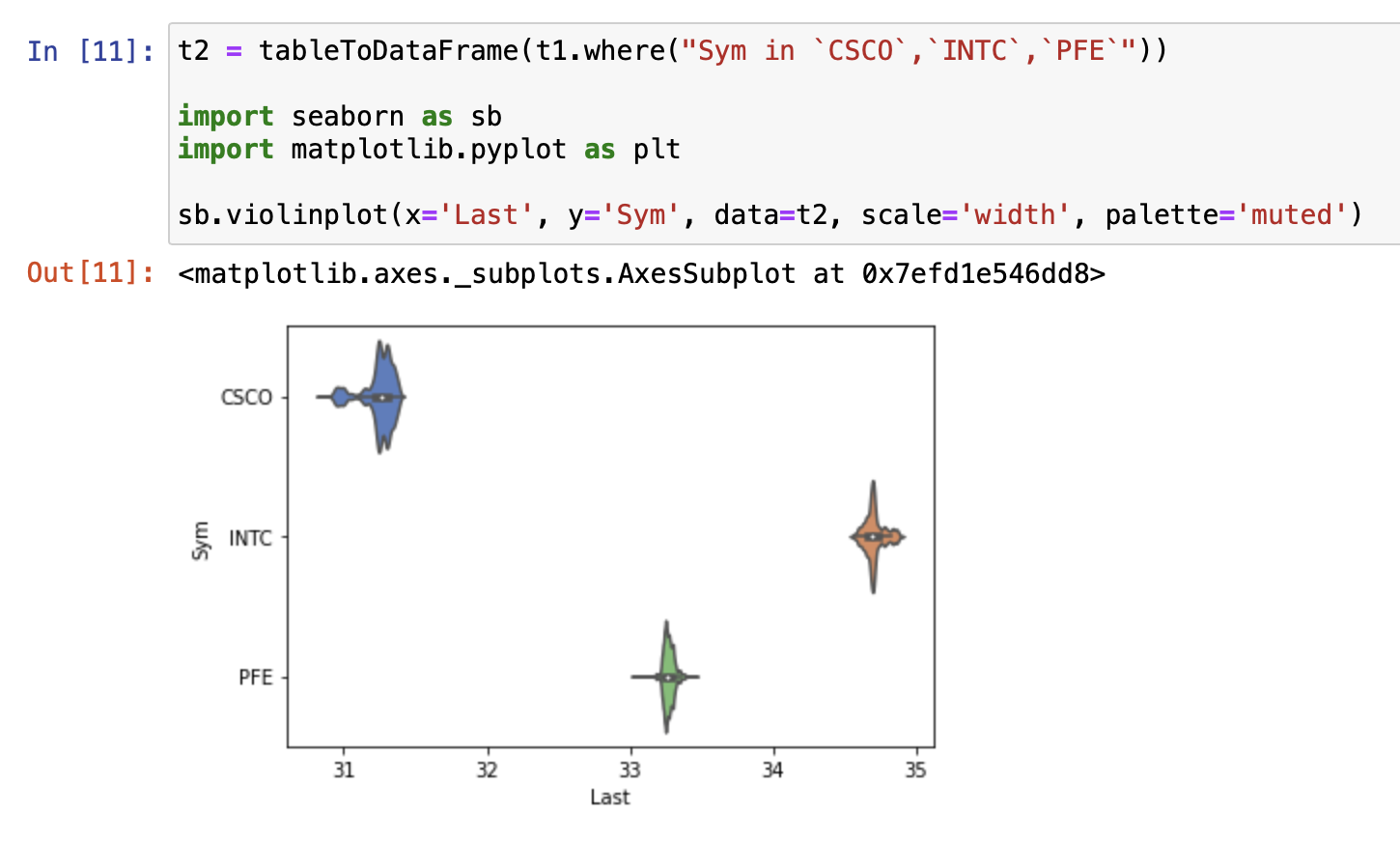
This kind of plot is only possible because we’re utilizing Deephaven through Jupyter. Through this plot, we can clearly see that there is a difference between all three average trading prices here. However, in many other contexts, this difference may not be so obvious and we may need to employ a statistical test like ANOVA. Deephaven does not have in-built ANOVA functionality, but we can employ a common Python package called statsmodels to do the legwork for us.
We will use ANOVA to test the hypothesis that at least one of these group means differs from the rest. Again, this is obvious from the plot, so performing the test is almost redundant, but this is not generally the case. The point is that, since we’re using Deephaven through Jupyter, it’s easy to have the plot and the test all in the same place:

With the high F-value here, we can confirm that there really is at least one average trading price that is different from the others. More importantly, we can see just how easy it was to create the plot and perform the test; it would not have been so easy with Deephaven alone, but combining Deephaven with Jupyter has given us a powerful tool for statistical analysis, presentation, and modelling when dealing with high throughput data.
See also:
Check out our blog series on COVID-19 modelling that demonstrates some of the plotting possibilities when using Deephaven with Jupyter.
Conclusion#
As we’ve seen, Deephaven has made it very easy to connect Deephaven servers, databases, and optimized query language to a Jupyter script that can leverage the extensive array of Python libraries for plotting, intricate data analysis, and more. While Deephaven's File Explorer/Notebook integration with the Web IDE and Code Studio is more interactive - for instance, using our notebooks supports creating persistent queries and scheduling apps, Jupyter's "lab notebook" style is familiar to many users and and seems to be the quintessential Python environment for many data scientists. Deephaven on its own and Jupyter powered by Deephaven can be used for different workflows. We hope you find this useful and exciting, because there is almost no data problem that this synergy cannot solve.