Downsample Imports
Downsample imports are used to import a downsampled version of data from an existing time-series table into an intraday partition. The target table must already exist. Unlike other styles of import, Deephaven provides no "schema creator" tool, as the target table typically takes a very similar or identical form to the source table.
Quickstart
The following is an example of how to run a downsample import from the command line (This document also describes how to import via a script or a Deephaven UI Import Job). This example assumes a typical Deephaven installation and that the target table already exists.
sudo -u dbmerge iris_exec downsample_import -- \
-ns TargetNamespace -tn TargetQuoteTable \
-sn SourceNamespace -st SourceQuoteTable -sp 2018-09-26 \
-tc Timestamp -p 00:00:10 -kc Sym -last Bid,Ask,BidSize,AskSize \
-dp localhost/2018-09-26
This example downsamples the 2018-09-26 partition of the table SourceNamespace.SourceQuoteTable and stores the result in the target table (TargetNamespace.TargetQuoteTable). The Timestamp column is used to downsample the source table every 10 seconds for each key. "Sym" is identified as the key column, and the last values from each time interval from the Bid, Ask, BidSize and AskSize columns are selected.
Import Query
When Import - Downsample is selected, the Persistent Query Configuration Editor window shows the following options:
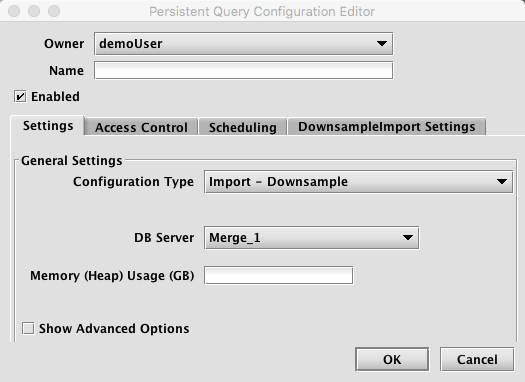
To proceed with creating a query to import downsampled data, you will need to select a merge server and enter the desired value for Memory (Heap) Usage (GB).
Options available in the Show Advanced Options section of the panel are typically not used when importing or merging data. To learn more about this section, please refer to the Persistent Query Configuration Viewer/Editor.
The Access Control tab presents a panel with the same options as all other configuration types, and gives the query owner the ability to authorize Admin and Viewer Groups for this query. For more information, please refer to Access Control.
Clicking the Scheduling tab presents a panel with the same scheduling options as all other configuration types. For more information, please refer to Scheduling.
Clicking the DownsampleImport Settings tab presents a panel with the relevant options:
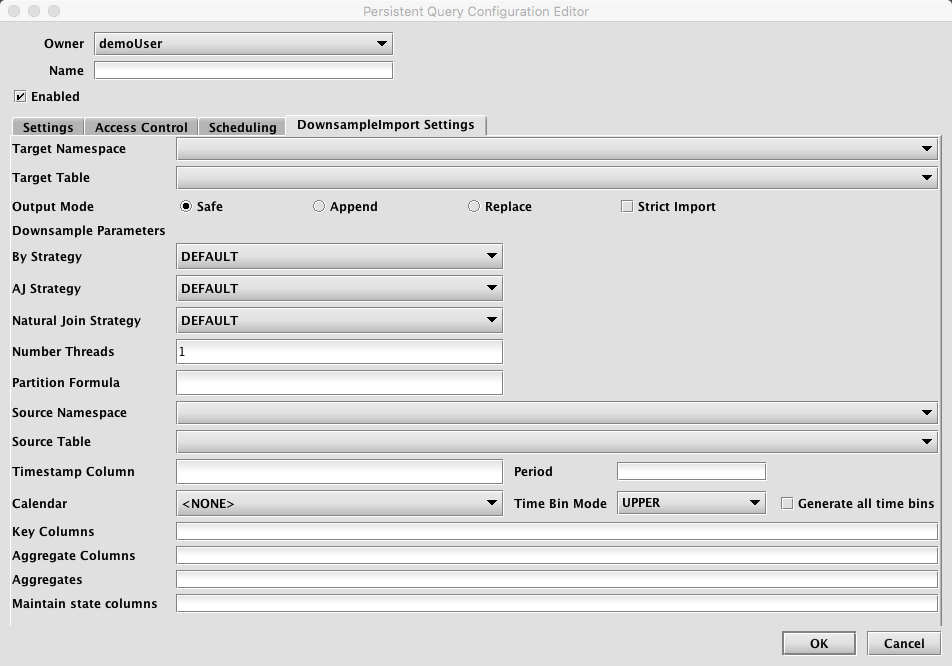
Downsample Import Settings
- Target Namespace: This is the namespace into which you want to import the file.
- Target Table: This is the table into which you want to import the data. The schema of this table must be consistent with the output of the downsampling process (as specified by the other options on this panel).
- Output Mode: This determines what happens if data is found in the fully-specified partition for the data. The fully-specified partition includes both the internal partition (unique for the import job) and the column partition (usually the date).
Safe- if existing data is found in the fully-specified partition, the import job will fail.Append- if existing data is found in the fully-specified partition, data will be appended to it.Replace- if existing data is found in the fully-specified partition, it will be replaced. This does not replace all data for a column partition value, just the data in the fully-specified partition.Strict Import: has no meaning (at present) for this type of import.
- Downsample Parameters
- By Strategy - The Deephaven "byStrategy" to use when performing the downsample aggregate operations.
- AJ Strategy - The Deephaven join strategy to use when joining source data to time bins (applicable only when
setAllBins(true)). - Natural Join Strategy - The Deephaven join strategy to use when filtering time bins.
- Number Threads - the number of threads to use when downsampling. For large downsampling jobs where "generate all time bins" is true, this can improve performance by parallelizing the downsample time-join on a per-key basis.
- Partition Formula: Specifies which source column partition to import. This style of import supports only single-partition imports. A typical value for this might be
currentDateNy(). - Source Namespace: Namespace of the table that will be downsampled.
- Source Table: Name of the table to downsample. This table must contain the timestamp and key columns specified in this panel. For performance reasons, it is recommended that large source tables be grouped by the key column(s).
- Timestamp Column: Name of the column in the source table to use for generating time bins. Must be of type DBDateTime.
- Period: Interval to use for generating time bins in HH:MM:SS format. Examples: 00:05:00 for 5 minute bins, 00:01:00 for 1 minute bins.
- Calendar: The name of a calendar to use for filtering time stamps.
- Time Bin Mode: How to assign timestamps in the source data to time bins. Given the time of 01:32:34 and a period of 5 minutes,
UPPERwould assign this time to the 01:35:00 bin, whileLOWERwould assign to the 01:30:00 bin.UPPERis a more typical choice. - Generate All Time Bins: Whether or not to generate time bins for the entire time range spanned by the underlying data, even if no data falls into the bin. Setting this to true requires one or more joins and hence will cause the downsampling process to be significantly slower.
- Key Columns: Optional columns to use for grouping the source data. The downsampling will produce a row for each (time bin, key) combination. For financial series, the instrument identifier is a typical choice for this.
- Aggregate Columns: Comma separated list of aggregate/data columns names desired in the downsampler output. These may match columns in the source table or rename then using the
OutputColumn=OriginalColumnformat. Typically the latter would be used for additional aggregates of source columns (for exampleVolume=Sizeused in combination with asumaggregate on trade data). - Aggregates: Comma separated list of aggregates to use for each column specified in the Aggregate Columns field. There number of aggregates must exactly match the number of aggregate columns. Legal values for aggregates are:
Last, First, Sum, Min, Max, Avg, Std, Var, Array(Countis not available). - Maintain State Columns: Comma separated list of columns for which to maintain state from one time bin to the next if no data when generating all time bins. Typically would be used for
Lastaggregate columns where the value is "good until changed" (such asBidandAskin quote data).
Importing Using Builder
Downsample imports may be performed from inside a Deephaven Groovy or Python script. This permits more elaborate logic with respect to existing data. These scripts may be executed as a persistent query or from the command line using the iris_exec "run_local_script" tool. All imports should be performed as the dbmerge user (or from a persistent query, running on a merge server).
The DownsampleImport class provides a static builder method, which produced an object used to set parameters for the import. The builder returns an DownsampleImport object from the build() method. Imports are executed via the run() method and if successful, return the number of rows imported. All other parameters and options for the import are configured via the setter methods described below. The pattern when executing a Downsample Import follows:
nRows = DownsampleImport.builder(<db>, <namespace>, <table>, <timestamp column>, <period>, <key column>...)
.set<option>(<option value>)
...
.build()
.run()
Required Builder Parameters
|
Parameter |
Type |
Req? |
Default |
Description |
|---|---|---|---|---|
|
db |
Database |
Yes |
N/A |
The Deephaven database (typically " |
|
namespace |
String |
Yes |
N/A |
The target table namespace. |
|
table |
String |
Yes |
N/A |
The target table name. |
|
Timestamp column |
String |
Yes |
N/A |
Name of the time column in the source table used for time sampling. The output time bin column will be the same as this unless it is renamed by specifying this as a pair (i.e. |
|
period |
String |
Yes |
N/A |
Time interval for sampling in HH:MM:SS format. |
|
key column... |
String(s) |
Yes |
N/A |
Zero or more "key columns", used to group the data. There will be one row in the output for each distinct key value per time interval. |
Import Options
|
Option Setter |
Type |
Req? |
Default |
Description |
|---|---|---|---|---|
|
setDestinationPartitions |
String |
No* |
N/A |
The destination partition(s). e.g., " |
|
setDestinationDirectory |
File | String |
No* |
N/A |
The destination directory. e.g., |
|
setOutputMode |
ImportOutputMode | String |
No |
SAFE |
Enumeration with the following options:
May also be specified as String (e.g.," |
|
setStrict |
boolean |
No |
true |
If true, will allow target columns that are missing from the source to remain null, and will allow import to continue when data conversions fail. In most cases, this should be set to false only when developing the import process for a new data source. |
|
setPartitionColumn |
String |
No |
N/A |
Column name to use to choose which partition to import each source row. |
|
|
|
|
|
|
|
setSourceTable |
Table |
Yes |
N/A |
Source table to downsample |
|
setTimeBinMode |
String | Downsampler.TimeBinMode |
No |
UPPER |
Must be |
|
setAllBins |
boolean |
No |
false |
Indicates whether or not to generate all time bins over the interval covered by the source table. If false, only intervals for which source data exists will be generated. |
|
setMaintainStateColumns |
String... |
No |
N/A |
Indicates a subset of one or more output columns that should "maintain state", or maintain the same value from one time interval to the next even if no new data is observed. Typically used with |
|
setByStrategy |
String | Table.ByStrategy |
No |
DEFAULT |
The Deephaven " |
|
setAjStrategy |
String | Table.JoinStrategy |
No |
DEFAULT |
The Deephaven join strategy to use when joining source data to time bins (applicable only when |
|
setNaturalJoinStrategy |
String | Table.JoinStrategy |
No |
DEFAULT |
The Deephaven join strategy to use when filtering time bins. |
|
setCalendar |
String |
No |
N/A |
A Deephaven calendar to use for filtering output time bins. |
|
setNumThreads |
int |
No |
1 |
Maximum number of threads to use when downsampling. Downsampling can be parallelized to some extent if key columns are present. |
|
setLogger |
Logger |
No |
Default logger |
Deephaven logger object for logging progress. |
|
addAggregates |
ComboAggregateFactory.ComboBy... |
No |
N/A |
Add the given aggregates to the downsampling process for generating output data columns. Typically it is easier to apply the methods for specific operations (" |
|
addAggregate |
AggType, String |
No |
N/A |
Add the given aggregate to the downsampling process for generating output data columns. Typically it is easier to apply the methods for specific operations (" |
|
addLastColumns |
String... |
No |
N/A |
Add the given columns to the downsample output, to be generated by a |
|
addFirstColumns |
String... |
No |
N/A |
Add the given columns to the downsample output, to be generated by a |
|
addMinColumns |
String... |
No |
N/A |
Add the given columns to the downsample output, to be generated by a |
|
addMaxColumns |
String... |
No |
N/A |
Add the given columns to the downsample output, to be generated by a |
|
addSumColumns |
String... |
No |
N/A |
Add the given columns to the downsample output, to be generated by a |
|
addStdColumns |
String... |
No |
N/A |
Add the given columns to the downsample output, to be generated by a |
|
addVarColumns |
String... |
No |
N/A |
Add the given columns to the downsample output, to be generated by a |
|
addAvgColumns |
String... |
No |
N/A |
Add the given columns to the downsample output, to be generated by a |
|
addArrayColumns |
String... |
No |
N/A |
Add the given columns to the downsample output, to be generated by a |
Import from Command Line
Downsample imports from the command line work in a very similar way to the scripted imports. The primary difference is that since the source table is specified by name (instead of a Table object), you must also supply a source partition (i.e., Date) from which to import.
The syntax for running downsample imports from the command line is described below. You may also issue the import command without arguments to see them described in the console.
Command Reference
iris_exec downsample_import <launch args> -- <downsample import args>
-dd or --destinationDirectory <path>
-dp or --destinationPartition <internal partition name / partitioning value> | <internal partition name>
-pc or --intradayPartition <partition column name>
-ns or --namespace <namespace>
-tn or --tableName <name>
-om or --outputMode <import behavior>
-rc or --relaxedChecking <TRUE or FALSE>
-sn or --sourceNamespace <source namespace>
-st or --sourceTable <source table>
-tc or --timestampColumn <timestamp column>
-p or --period <period>
-kc or --keyColumns <key columns>
-sp or --sourcePartition <source partition>
-timeBinMode <LOWER or UPPER>
-allBins <true or false>
-maintainStateColumns <maintain state columns>
-byStrategy <by strategy>
-ajStrategy <aj strategy>
-naturalJoinStrategy <natural join strategy>
-last <last columns>
-first <first columns>
-sum <sum columns>
-min <min columns>
-max <max columns>
-std <standard deviation columns>
-var <variance columns>
-avg <average columns>
-array <array columns>
Downsample Import Arguments
|
Parameter Value |
Description |
|---|---|
|
-dd -dp -pc |
Either a destination directory, specific partition, or internal partition plus a partition column must be provided. A directory can be used to write a new set of table files to specific location on disk, where they can later be read with TableTools. A destination partition is used to write to intraday locations for existing tables. The internal partition value is used to separate data on disk; it does not need to be unique for a table. The name of the import server is a common value for this. The partitioning value is a string data value used to populate the partitioning column in the table during the import. This value must be unique within the table. In summary, there are three ways to specify destination table partition(s):
|
|
-ns |
|
|
-tn |
|
|
-om |
|
|
-rc |
|
|
-sn |
|
|
-st |
|
|
-tc |
|
|
-p |
|
|
-kc |
|
|
-sp |
|
|
-timeBinMode |
|
|
-allBins |
|
|
-maintainStateColumns |
|
|
-byStrategy |
|
|
-ajStrategy |
|
|
-naturalJoinStategy |
|
|
-calendar |
|
|
-last |
|
|
-first |
|
|
-min |
|
|
-max |
|
|
-sum |
|
|
-std |
|
|
-var |
|
|
-avg |
|
|
-array |
|
Last Updated: 25 February 2020 08:25 -05:00 UTC Deephaven v.1.20200121 (See other versions)
Deephaven Documentation Copyright 2016-2020 Deephaven Data Labs, LLC All Rights Reserved