Binary Log Tailer
Introduction
The log tailer is a Deephaven process that looks for binary log files generated by application and Deephaven loggers, and then sends the data contained in these log files to the Data Import Server (DIS) for intraday storage. The process of reading the binary log files is referred to as "tailing" as it is analogous to the Linux tail command. One or more tailers can run at the same time, with each tailer's configuration specifying the files it tails and where its data is sent. All data is loaded into the appropriate internal partition based on the tailer's configuration and the log file names, and the column partition information is always embedded in the log file names.
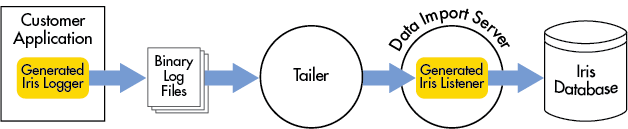
Each tailer is given a name, which is usually specified through a Java parameter when the tailer is started. For example, on a standard Linux Deephaven installation the command sudo service iris start tailer 1 starts a tailer called "1". This name is used in various configuration parameters and does not need to be numeric.
It is generally recommended a tailer be run on the nodes on which data is produced as this provides the best performance for finding and processing binary log files. A tailer can process many different tables simultaneously, as well as send data to different destinations. One tailer is generally enough, but it is possible to run more than one tailer on any node to enable independent restarts for different configurations.
Tailer configuration consists of two parts. Process-level configuration, such as the tailer's name and destinations, is handled through properties retrieved from Deephaven property files. Configuration related to specific tables and logs for a tailer is retrieved from tailer-specific XML files. Tailer configuration is detailed in the Property File Configuration Parameters and Tailer XML Configuration Parameters sections.
There is also a quick start guide to setting up a simple new tailer that looks for one table.
Intraday Partitioning
Deephaven partitions all intraday data into separate directories, in effect creating multiple sets of data files spread across these directories. When querying intraday data, or merging it into the historical database, all of the intraday partitioning directories are combined into a single table. In most cases users are not directly aware of this partitioning, but configuring the tailer requires an in-depth understanding of this partitioning if it is to be used correctly.
Deephaven is highly optimized for appending data to tables. To accomplish this, it is required that only one data source causes data to be written to a given set of underlying intraday data files at any time. This is one of the primary reasons for intraday partitioning. Since most real-time data sources will use Deephaven loggers to generate data, and this data will be sent through the tailer, it is the tailer that determines the appropriate internal partition directories into which this intraday data will be appended.
There are two levels of partitioning that the tailer will determine when it sends data to the DIS. When the tailer is configured to set up both of these levels properly, it ensures the data is separated appropriately. The DIS will create distinct directories at each level of partitioning, and the lowest-level subdirectories will each contain a set of data files for the table.
- Internal partitions are the first level of partitioning. Internal partitions usually correspond to a data source. The tailer configuration usually determines the internal partition value from a binary log file name, possibly applying information from its configuration to further distinguish it. Internal partitions are not determined by the schema. The internal partition is also called the destination partition in some Deephaven tools, such as importers.
- Column partitions divide the data based on the partitioning column specified in the table's schema, a String column that frequently contains a date value. The tailer determines the column partition value based on a log file name. For date-based column partitioning, the value is usually in yyyy-MM-dd format (e.g., 2017-04-21).
Binary Log Filename Format
The tailer runs in a configuration where it automatically monitors binary log directories for new files, looking for new partitions and processing them appropriately. To assist in these file searches, binary log filenames must be in a standard format, with several parts separated by periods. Support is provided for filenames in other formats, but this requires additional configuration (explained later).
<Namespace>.<Table Name>.<System or User>.<Internal Partition>.<Column Partition>.bin.<Timestamp>
- The first part should indicate the table's namespace.
- The second part should indicate the table's name.
- The third part should indicate the table's type ("System" or "User").
- The fourth part should indicate the internal partition value.
- The fifth part should indicate the column partition value.
- Next comes the
.bin.binary log file identifier. - Finally, the date and time the file was created to help with file sorting.
The following example from a Deephaven internal table illustrates a typical filename:
DbInternal.AuditEventLog.System.vmhost1.2018-07-23.bin.2018-07-23.135119.072-0600
DbInternal- the table's namespace.AuditEventLog- the table's name.System- the type of table, in this case belonging to a system namespace. User indicates a user namespace.vmhost1- the internal partition used to distinguish a data source, usually a host name.2017-07-23- the column partition value. This is frequently a date in yyyy-MM-dd format (or another specified format that includes the same fields), but any partitioning method may be used as long as the filename can be used to distinguish the partition..bin.- the file identifier that distinguishes this as a Deephaven binary log file. The standard identifier is ".bin.".2018-07-23.135119.072-0600- a timestamp so the files can be processed in order. The standard format used in this example is a timestamp down to the millisecond inyyyy-MM-dd.HHmmss.SSSformat, followed by timezone offset. The timezone offset is important to correctly sort files during daylight-savings transitions.
Bandwidth Throttling
The tailer configuration provides the option to throttle the throughput of data sent to specific destinations, or the throughput sent for a specific log entry (per destination). This should only be used if network bandwidth is limited or issues have been encountered due to unexpected spikes in the amount of data being processed by the tailer. Because it restricts how quickly the tailer will process binary log files, use of this feature can cause Deephaven to fall behind in getting real-time data into the intraday database. Throttling is optional and will not be applied unless specified.
Two types of throttling are supported.
- Destination-level throttling is applied to each destination (data import server), and is specified in the tailer's property files (see the
data.import.server.<name>.throttleKBytesproperty). It is shared within a tailer for all data sent to that destination. - Log-entry-level throttling is applied to each destination for each log entry in the XML file, and is applied across all partitions for that log entry. It is specified with the
maxKBpsattribute in a log entry.
Throttles are always specified in kilobytes per second (KBps). Because the binary log files are sent directly to the data import servers without translation, the size of the binary log files can give an indication of the required bandwidth for a given table. For example, if a particular table's binary log files are sized at 1GB each hour, then an approximate bandwidth requirement could be calculated as follows:
- Since throttles are specified in KBps, first translate GB to KB: 1GB = 1,024MB = 1,048,576 KB.
- Next, divide the KB per hour by the number of seconds in an hour: 1,048,576 KB per hour / 3,600 seconds per hour = 291.3KB per second.
- In this case, setting a 300KBps throttle would ensure that each hour's data could be logged, but latency will occur when data delivery to the log file spikes above the specified 300 KB/s throttle rate.
Throttling uses a token bucket algorithm to provide an upper bandwidth limit and smoothing of peaks over time. The token bucket algorithm requires, at a minimum, enough tokens for the largest messages Deephaven can send, and this is calculated by the number of seconds (see the log.tailer.bucketCapacitySeconds property) times the KBps for the throttle. At the current time, Deephaven sends maximum messages of 2,048KB (2MB), so the number of seconds in the bucket times the bandwidth per second must equal or exceed 2,048K. The software will detect if this is not true and throw an exception that prevents the tailer from starting.
The bucket capacity also impacts how much bandwidth usage can spike, as the entire bucket's capacity can be used at one time.
- If
log.tailer.bucketCapacitySecondsis 10, and a throttle allows 10KBps, then the maximum bucket capacity is 100KB, which is not sufficient for Deephaven; the bucket would never allow the maxiumum 2,048KB message through. Deephaven will detect this and fail. - If
log.tailer.bucketCapacitySecondsis 60, and a throttle allows 1000KBps, then the bucket's capacity is 60,000K. If a large amount of data was quickly written to the binary log file, the tailer would immediately send the first 60,000K of data to the DIS. After that the usage would level out at 1,000KBps. The bucket would gradually refill to its maximum capacity once the data arrival rate dropped below 1,000KBps, until the next burst.
Binary Log File Managers
The tailer must be able to perform various operations related to binary logs.
- It must derive namespace, table name, internal partition, column partition, and table type values from binary log filenames and the specified configuration log entry.
- It must determine the full path and file prefix for each file pattern that matches what it is configured to search for.
- It must sort binary log files to determine the order in which they will be sent.
These operations are handled through the use of Java classes called binary log file managers. Two binary log file managers are provided.
StandardBinaryLogFileManager- this provides functionality for binary log files in the standard format described above (<namespace>.<table name>.<table type>.<internal partition>.<column partition>.bin.<date-time>)DateBinaryLogFileManager- this provides legacy functionality for binary log files using date-partitioning in various formats
A default binary log file manager will be used for all log entries unless a specific log entry overrides it with the fileManager XML attribute. The log.tailer.defaultFileManager property specifies the default binary log file manager. The default value of this property specifies the DateBinaryLogFileManager.
For the tailer to function correctly, file names for each log must be sortable. Both binary log file manager types will take into account time zones for file sorting (including daylight savings time transition), assuming the filenames end in the timezone offset (+/-HHmm, for example "-0500" to represent Eastern Standard Time). The standard Deephaven Java logging infrastructure ensures correctly-named files with full timestamps and time zones. Note that time zones are not taken into account by the DateBinaryLogFileManager in determining the date as a column partition value, only in determining the order of generated files; the column partition's date value comes from the filename and is not adjusted.
Tailer Configuration
Deephaven property files and tailer-specific XML files are used to control the tailer's behavior.
- Property definitions - tailer behavior that is not specific to tables and logs is controlled by property definitions in standard Deephaven property files. This includes destination details and binary log file directories to be monitored.
- Table and log definitions - detailed definitions of the binary logs containing intraday data, and the tables to which those logs apply, is contained in XML configuration files. Each log entry in these XML files corresponds to a single binary log file manager instance.
Property File Configuration Parameters
This section details all the tailer-related properties that are read from the property file specified by the Configuration.rootFile Java parameter (usually specified in the host confguration with the CONFIGFILE environment variable, such as CONFIGFILE=iris-tailer1.prop).
Properties may be specified in tailer property files, or passed in as Java parameters with the -D prefix (e.g., -DParameterName=ParameterValue).
Configuration File Specification
These parameters determine the processing of XML configuration files, which are read during tailer startup to build the list of logs that are handled by the tailer.
log.tailer.configs- a comma-delimited list of XML configuration files, which define the tables being sent. For example, the tailer that handles the internal binary logs has the following definition:log.tailer.configs=tailerConfigDbInternal.xmllog.tailer.processes- a comma-delimited list of processes for which this tailer will be sending data. Each process should correspond to a "Process" tag in the XML configuration files. If the list is empty or not provided then the tailer will run but not handle any binary logs. If it includes an entry with a single asterisk ("*"), the XML entries for all processes are used. Otherwise the tailer only reads the entries from the XML configuration files for the processes listed therein (and any entries with a Process name of "*").log.tailer.processes=iris_controller,customer_logger_1
Destination Parameters
These parameters specify details for the destinations (Data Import Servers) to which the tailer will send data. Destination definitions apply across all tailers, while the tailer ID is used to specify the appropriate default destinations for a given tailer.
intraday.tailerID- specifies the tailer ID (name) for this tailer; this ID is used to determine which destinations will be used as the default destinations for the tailer. This is usually set by the startup scripts in the Java parameters rather than in the property file. For example, if the iris scripts are used,sudo service iris start tailer 1will causeintraday.tailerIDto be set to 1 when the tailer is started; alternatively, the Java command line argument-Dintraday.tailerID=1will have the same effect. The parameter can also be specified in the property file if desired.intraday.tailerID=customer1log.tailer.enabled.<tailer ID>- If this is true, then the tailer will start normally. If this is false, then the tailer will run without tailing any files.log.tailer.enabled.customer1=truedata.import.server.<name>.host- a named destination host for a Data Import Server (DIS) along with its network address. The name is assigned by the customer and must not not contain periods or spaces. The name will be used to retrieve other optional destination properties for that DIS. The specified host can be an IP address or hostname.data.import.server.prod.host=25.25.25.25data.import.server.test.host=testing1.customer.comdata.import.server.<name>.port- if specified, the port on which the DIS will be listening for the named destination. If not supplied for a named destination, the default port from the data.import.server.port property will be used.data.import.server.vmhost1.port=40000data.import.server.port- the default port on which the DIS processes will be listening. Unless a given destination name has a port entry, this port will be used. This is a required property.data.import.server.port=22021data.import.server.<name>.throttleKBytes- specifies the maximum bandwidth allocated to the named destination in kilobytes per second. A destination throttle is applied across all data being sent to that destination, in addition to any log-level throttles (see the XML Configuration Parameters). If this parameter is not supplied for a given destination name, then no throttling is applied for the destination (log-level throttling may still be applied).data.import.server.test.throttleKBytes=512log.tailer.bucketCapacitySeconds- the capacity in seconds for each bucket used to restrict the bandwidth to the Data Import Servers. This is applied independently to every throttle, both the destination-level throttles specified by thedata.import.server.<name>.throttleKBytesparameter, and the log-level throttles specified in the XML. It must be large enough to handle the largest possible messages, as explained in the bandwidth throttling section. If the parameter is not provided, it defaults to 30 seconds.log.tailer.bucketCapacitySeconds=120log.tailer.<tailer ID>.defaultDestinations- specifies the destination names to which data is sent for the specified tailer ID. If this is supplied, then data is only sent to these specified destinations unless a log entry's XML configuration specifies otherwise. If it is not supplied, a tailer will send data to all specified destinations unless a log entry's XML configuration specifies otherwise. The supplied names must match the names fromdata.import.server.<name>.hostparameters.log.tailer.1.defaultDestinations=prodlog.tailer.retry.count- this optional parameter specifies how many times each destination thread will attempt to reconnect after a failure. The default isInteger.MAX_VALUE, effectively imposing no limit. Once this limit is reached for a given table/destination/internal partition/column partition set, the tailer will no longer attempt to reach the destination unless new files cause it to restart the connection. A value of 0 is valid and means that only one connection attempt will be made.log.tailer.retry.pause- the pause, in milliseconds, between each reconnection attempt after a failure. The default is 1000 milliseconds (1 second).log.tailer.poll.pause- the pause, in milliseconds, between each poll attempt to look for new data in existing log files or find new log files when no new data was found. A lower value will reduce tailer latency but increase processing overhead. The default is 1000 milliseconds (1 second).
File Watch Parameters
The tailer will watch for new files to send to its Binary Log File Manager instances for possible tailing, using underlying infrastructure. The logic used to watch for these files can be changed. This parameter should only be changed under advice from Deephaven Data Labs.
log.tailer.watchServiceType- a parameter that specifies the underlying watch service implementation. Options are:JavaWatchService- an implementation that uses the built-in Java watch service. On most Linux implementations this is the most efficient implementation and can result in quicker file notifications, but it does not work correctly on shared file systems such as NFS when files are created remotely.PollWatchService- a poll-based implementation that works on all known file systems but may be less efficient and consume more resources than theJavaWatchServiceoption.log.tailer.watchServiceType=JavaWatchService
Miscellaneous Parameters
The following additional parameters control other aspects of the tailer's behavior.
log.tailer.defaultFileManager- specifies which binary log file manager is used for a log unless that log's XML configuration entry specifies otherwise. The default binary log file manager handles date-partitioned tables; if a different default binary log file manager is desired, then the parameter should be updated accordingly.log.tailer.defaultFileManager=com.illumon.iris.logfilemanager.DateBinaryLogFileManagerlog.tailer.defaultIdleTime- if the tailer sends no data for anamespace/table/internal partition/column partitioncombination for a certain amount of time (the "idle time"), it will terminate the associated threads (these threads will be restarted if new files appear). This parameter specifies the default idle time after which this occurs. This is normally set for 01:10, which is a little more than the Deephaven logging infrastructure's binary log file rollover time.log.tailer.defaultDirectories- an optional comma-delimited list of directories which specify where this tailer should look for binary log files. If not specified, the tailer's process log directory will be used. This defaults to<workspace>/../logs, but can be overridden by settinglogDirin the JVM arguments (e.g.,-DlogDir=/tmp/Tailer1)log.tailer.defaultDirectories=/Users/app/code/bin1/logs,/Users/app2/data/logs
log.tailer.logDetailedFileInfo- a boolean parameter that specifies whether the tailer logs details on every file every time it looks for data. The default value is false, which means the tailer only logs file details when it finds new files.log.tailer.logDetailedFileInfo=false
log.tailer.logBytesSent- a boolean parameter that specifies whether the tailer logs information every time it sends data to a destination. The default value is true, which means the tailer logs details every time it sends data to a DIS.log.tailer.logBytesSent=true
Date Binary Log File Manager Parameters
log.tailer.timezone- this optional parameter is used to specify the time zone used for log processing. If it's not specified, the timezone will be the time zone on which the server runs. It can be used in the calculations of the path patterns for date-partitioned logs and tables, but is not used in other aspects of the tailer's operation. These time zone names come from the DBTimeZone class.log.tailer.timezone=TZ_NY
log.tailer.internalPartition.prefix- the prefix for the tailer's internal partition, which will be used by anyDateBinaryLogFileManagerinstances to determine the start of the internal partition name, if the name is not being determined from the logs' filenames (the partition suffix from each log's configuration entry will be appended to this prefix to generate the complete internal partition name). If this is not provided, the tailer will attempt to determine the name of the server on which it is running, and use this as a prefix instead. If the tailer cannot determine a name,localhostis used.log.tailer.internalPartition.prefix="source1"
Tailer XML Configuration Parameters
Details of the logs to be tailed are supplied in XML configuration files. The list of XML files is specified by the log.tailer.configs parameter.
Configuration File Structure
Each tailer XML configuration file must start with the <Processes> root element. Under this element, one or more <Process> elements should be defined.
<Process> elements define processes that run on a server, each with a list of Log entries which define the binary log file manager details for the tailer. Each <Process> element must have a name that specifies the application process that generates the specified logs; the log tailer uses the log.tailer.processes property value to determine which <Process> entries to use from its XML configuration files. For example the following entry specifies two binary log file managers for the db_internal process; a tailer that includes db_internal in its log.tailer.processes parameter would use these binary log file managers. Each parameter is explained below.
<Processes>
<Process name="db_internal">
<Log filePatternRegex="^DbInternal\.(?:[^\.]+\.){2}bin\..*"
tableNameRegex="^(?:[^\.]+\.){1}([^\.]+).*"
namespace="DbInternal"
internalPartitionRegex="^(?:[^\.]+\.){2}([^\.]+).*"
path=".bin.$(yyyy-MM-dd)" />
<Log fileManager="com.illumon.iris.logfilemanager.StandardBinaryLogFileManager" />
</Process>
</Processes>
If the <Process> name is a single asterisk ("*"), every tailer will use that Process element's Log entries regardless of its log.tailer.processes value.
Each Log element generates one binary log file manager instance to handle the processing of the associated binary log files. Binary log files are presented to each binary log file manager in the order they appear in the XML configuration files. Once a file manager claims the file, it is not presented to any other file managers.
To see an example of how to set up a customer tailer, see Tailer Quick Start Guide.
Binary Log File ManagerTypes
Each Log element specifies information about the binary log files which a tailer processes. The attributes within each Log entry vary depending on the type of binary log file manager chosen. Full details on each attribute are provided in the Log Element Attributes section.
Both binary log file managers allow the following optional attributes to override default tailer parameters; each is explained in detail later.
idleTimechanges the default idle time for when threads are terminated when no data is sentfileSeparatorchanges the default file separator from .bin.destinationsspecifies to which Data Import Servers the data will be sentlogDirectoryorlogDirectorieschanges the directories in which the binary log file manager will look for filesexcludeFromTailerIDsrestricts a Log entry from tailers running with the given IDsmaxKBpsspecifies a Log-level throttle
Standard Binary Log File Manager
The StandardBinaryLogFileManager looks for files named with the default <namespace>.<table name>.<table type>.<internal partition>.<column partition>.bin.<date-time> format. It will be the most commonly used file manager, as it automatically handles files generated by the common Deephaven logging infrastructure.
- The namespace, table name, table type, internal partition, and column partition values are all determined by parsing the filename.
- The optional
namespaceornamespaceRegexattributes can restrict the namespaces for this binary log file manager. - The optional
tableNameortableNameRegexattributes can restrict the table names for this binary log file manager. - The optional
tableTypeattribute restricts the table type for this binary log file manager.
Date Binary Log File Manager
The DateBinaryLogFileManager requires further attributes to find and process files. It provides many options to help parse filenames, providing compatibility for many different environments.
- A
pathattribute is required, and must include a date-format conversion. It may also restrict the start of the filename. - If
pathdoes not restrict the filename , afilePatternRegexattribute should be used to restrict the files found by the binary log file manager. - A
namespaceornamespaceRegexattribute is required, to determine the namespace for the binary log files. - A
tableNameortableNameRegexattribute is required, to determine the table name for the binary log files. - The optional
internalPartitionRegexattribute can be specified to indicate how to determine the internal partition value from the filename. If theinternalPartitionRegexattribute is not specified, the internal partition will be built from thelog.tailer.internalPartition.prefixproperty or server name, and theinternalPartitionSuffixattribute. - The column partition value is always determined from the filename, immediately following the file separator.
- The table type is taken from the optional
tableTypeattribute. If this is not specified, then the table type isSystem.
Log Element Attributes
Unless otherwise specified, all parameters apply to both regular-expression entries and fully-qualified entries. These are all attributes of a <Log> element.
destinations- an optional comma-delimited list of destinations to which this entry's data will be sent. If it is supplied then it should use one or more names from the data.import.server.<name>.host parameters.destinations=prodPrimary,prodHotStandbyexcludeFromTailerIDs- an optional comma-delimited list, to cause this entry to be ignored for a tailer if its tailer ID matches one of the specified tailer IDs from this parameter. It may be used to force a tailer to ignore specific Log elements from a process that it would normally tail.excludeFromTailerIDs="CustomerTailer1"fileManager- a named binary log file manager for this Log. If defined, it can refer to either a named file manager from the tailer's XML configuration files, or a fully-qualified Java class.fileManager="BasicFiles"fileManager="com.customer.iris.CustomLogFileManager"filePatternRegex- a regular expression used to restrict file matches for a date binary log file manager. If the regular expression finds a match, then the file will be handled by the binary log file manager. The match is done through a group matcher, looking for the first matching expression.filePatternRegex="^[A-Za-z0-9_]*\.stats\.bin\.*"
fileSeparator- if the files to be handled by this binary log file manager do not include the standard .bin. separator, this specifies the separator to be used.fileSeparator="."
idleTime- the time (in the format HH:mm or HH:mm:ss) after which threads created by this binary log file manager will be terminated if no data has been sent.idleTime="02:00"
internalPartitionRegex- for date binary log file managers, a regular expression that will be applied to the filename to determine the internal partition. The match is done with a capture group, looking for the first matching expression. If this property is specified,log.tailer.internalPartition.prefixandinternalPartitionSuffixare ignored.internalPartitionRegex="^(?:[^\.]+\.){2}([^\.]+).*"
internalPartitionSuffix- for date binary log file managers, the suffix to be added to the internal partition prefix from thelog.tailer.internalPartition.prefixparameter to determine the intraday partition for this log.internalPartitionSuffix="DataSource1"
logDirectory- an optional parameter that specifies a single directory in which the log files will be found. If neitherlogDirectorynorlogDirectoriesare supplied, the tailer's default directories will be used. BothlogDirectoryandlogDirectoriescan not be supplied in the same Log element.logDirectory="/usr/app/defaultLogDir"
logDirectories- an optional comma-delimited list of directories that will be searched for files. If neitherlogDirectorynorlogDirectoriesare supplied, the tailer's default directories will be used. BothlogDirectoryandlogDirectoriescan not be supplied in the same Log element.logDirectories="/usr/app1/bin,/usr/app2/bin"
maxKBps- the maximum rate, in kilobytes per second, at which data can be sent to each Data Import Server for this Log element. This is applied per destination, but shared across all logs being tailed for the Log entry. It is applied independently of any destination-specific entries from the property files. See the bandwidth throttling section for further details.maxKBps="1000"
namespace- this parameter's meaning depends on the binary log file manager type. For a standard binary log file manager, it restricts the namespace that this file manager processes. If a file arrives for a namespace other than the defined value, it is not handled by this binary log file manager. For a date binary log file manager, it defines the namespace for this log entry. If it is not provided, thennamespaceRegexmust be supplied to determine the table name from the filename.namespace="CustomerNamespace"namespaceRegex- this parameter's meaning depends on the binary log file manager type. For a standard binary log file manager, it restricts the namespaces that this file manager processes. If the namespace doesn't match the regular expression, then files for that namespace are not handled by this file manager. For a date binary log file manager, it defines a regular expression that will be applied to the filename to determine the namespace. The match is done with a capture group, looking for the first matching expression.namespaceRegex="^(?:[^\.]+\.){0}([^\.]+).*"
path- for date binary log file managers, the filename for the specified log, not including directory. This may define the filename prefix, not including directory, and must include a date specification in the format$(<date formatting specification>). A typical entry will be in one of the following formats:<namespace>.<tablename>.bin.$(yyyy-MM-dd)- this restricts the filename to start with a given namespace and table name and specifies that the column partition value part of the filename is in theyyyy-MM-ddformat. This will usually be used in a Log element for a specific namespace and table. For example,path="CustomerNamespace.Table1.bin.$(yyyy-MM-dd)"path=".bin.$(yyyy-MM-dd)"- this indicates that there are no restrictions on the filename, and that the column partition value part of the filename is inyyyy-MM-ddformat. This will usually be used in combination with regular-expression attributes to determine namespaces and table names, and will usually additionally include afilePatternRegexattribute.
For date-partitioned logs, a date format sequence in the format
$(<date formatting expression>)is required as it is used to translate between file names and date partition values in the standard Deephavenyyyy-MM-dddate-partitioning format. For example, if the filenames use the formatyyyyMMdd, then the format sequence should be$(yyyyMMdd)and the tailer will automatically convert between this format and the Deephaven date partitioning standard. The date format sequence must immediately follow the file separator.tableName- this parameter's meaning depends on the binary log file manager type. For a standard binary log file manager, it restricts the table name that this file manager processes. If a file arrives for a table name other than the defined value, it is not handled by this binary log file manager. For a date binary log file manager, it defines the name of the table for this log entry. If it is not provided, thentableNameRegexmust be supplied to determine the table name from the filename.tableName="Table1"
tableNameRegex- this parameter's meaning depends on the binary log file manager type. For a standard binary log file manager, it restricts the table names that this file manager processes. If the table name doesn't match the regular expression, then files for that table name are not handled by this file manager. For a date binary log file manager, it defines a regular expression that will be applied to the filename to determine the table name. The match is done with a capture group, looking for the first matching expression.tableNameRegex="^(?:[^\.]+\.){0}([^\.]+).*"
tableType- this parameter's meaning depends on the binary log file manager type. For a standard binary log file manager, it restricts the table type that this file manager processes. If a file arrives for a table type other than the defined value, it is not handled by this binary log file manager. For a date binary log file manager, it defines the table type for this log entry. If it is not provided, then a table type ofSystemis used.tableType="User"
Regular Expression Example
It may be helpful to examine a standard set of regular expressions that may be used in common tailer configurations. A common filename pattern will be <namespace>.<tablename>.<host>.bin.<date/time>; the host will be used as the internal partition value. The following example filename provides an example of this file format:
EventNamespace.RandomEventLog.examplehost.bin.2017-04-01.162641.013-0600
In this example, the table name can be extracted from the filename with the following regular expression:
tableNameRegex="^(?:[^\.]+\.){1}([^\.]+).*"
The following table describes how this regular expression works:
^
|
ensures the regex starts at the beginning of the filename |
| (?: | starts a non-capturing group, which is used to skip past the various parts of the filename separated by periods |
| [^\.]+ | as part of the non-capturing group, matches any character that is not a period, requiring one or more matching characters |
| \. | as part of the non-capturing group, matches a period |
| ){1} | ends the non-capturing group and causes it to be applied 1 time; in matchers for other parts of the filename, the 1 will be replaced with how many periods should be skipped; this causes the regex to skip the part of the filename up to and including the first period |
| ([^\.]+) | defines the capturing group, capturing everything up to the next period, which in this case captures the table name |
| .* | matches the rest of the filename, but doesn't capture it |
For this example, the three attributes that would capture the namespace, table name, and internal partition are very similar, only differing by the number that tells the regex how many periods to skip:
namespaceRegex="^(?:[^\.]+\.){0}([^\.]+).*"
tableNameRegex="^(?:[^\.]+\.){1}([^\.]+).*"
internalPartitionRegex="^(?:[^\.]+\.){2}([^\.]+).*"
The above example could result in the following regular expression Log entry, which would search for all files that match the <namespace>.<tablename>.<host>.bin.<date/time> pattern in the default log directories:
<Log filePatternRegex="^[A-Za-z0-9_]+\.[A-Za-z0-9_]+\.[A-Za-z0-9_]+\.bin\..*" namespaceRegex="^(?:[^\.]+\.){0}([^\.]+).*" tableNameRegex="^(?:[^\.]+\.){1}([^\.]+).*"
internalPartitionRegex="^(?:[^\.]+\.){2}([^\.]+).*" runTime="25:00:00" path=".bin.$(yyyy-MM-dd)" />
Running a Tailer on Windows
The Iris log tailer (LogTailerMain class) should ideally be run on the same system where log files are being generated. Since this class has no dependency on *nix file system or scripting functionality, it can be run under Java as a Windows process or service when a Windows system is generating binary log data.
Requirements
To set up an installation under which to run the LogTailerMain class:
- Install Java SE runtime components or use the Illumon Launcher installation that included the Java JDK. The tailer typically can run with a JRE, but there are some advanced non-date partition features that would require the JDK. It is recommended to use the latest Java 1.8 install (v1.8.162 as of this writing.)
- Create a directory for a tailer launch command, configuration files, and workspace and logging directories. This directory must be accessible for read and write access to the account under which the tailer will run.
- Obtain the JAR files from a Deephaven installation (either copied from a server, or installed and/or copied from a client installation using the Deephaven Launcher).
- Create a launch command to provide the correct classpath, properties file, and other installation-specific values needed to run the tailer process.
- Configure startup for the tailer process.
Example directory
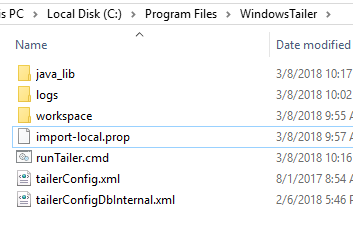
This directory was created under Program Files, where administrative rights will be needed by the account under which the tailer will run. In this example, the tailer is being run as a service under LocalSystem, but specific accounts with more limited rights would be valid as well. The key requirements are that the account must be able to write to the logs and workspace directories, must be able to read from all files to be tailed and all configuration and JAR files, and must have sufficient network access to contact the DIS.
Note that this directory contains a tailerConfig XML file, which specifies the tailer's configuration (i.e., which binary log files it will tail) and a property file, which specifies other tailer configuration options, including where the tailer will send the data. For full details on tailer configuration see Tailer Configuration. This directory also contains a logs and a workspace directory, which can be created empty, and a java_lib folder that was copied, with its JAR files, from the directory structure set up by the Deephaven Launcher client installer.
As new releases of Deephaven are applied to an environment, it will be necessary to update the JAR files in java_lib so any new tailer or tailer support functionality is also available to Windows-based tailer processes.
Launch Command
The launch command in this example is a Windows cmd file. It contains one line:
java -cp "C:\Program Files\WindowsTailer\java_lib\*";"C:\Program Files\WindowsTailer" -server -Xmx4096m -DConfiguration.rootFile=import-local.prop -Dworkspace="C:\Program Files\WindowsTailer\workspaces" -Ddevroot="C:\Program Files\WindowsTailer\java_lib" -Dprocess.name=tailer -Dlogging.processes=monitoring -Dintraday.tailerID=1 com.illumon.iris.logtailer.LogtailerMain
The components of this command follow:
java- Must be in the path and invoke Java 1.8
-
-cp "C:\Program Files\WindowsTailer\java_lib\*";"C:\Program Files\WindowsTailer"- The class path to be used by the process.
- The first part is the path to the JAR files from the Iris server or client install.
- The second part points to the directory that contains properties files and config XML files that the process will need.
-server- Run Java for a server process
-Xmx1024m- How much memory to give the process. This example is 1GB, but smaller installations (tailing less files concurrently) will not need this much memory. 1GB will be sufficient for most environments but if a lot of logs are tailed or data throughput is fairly high this may need to be increased.
-DConfiguration.rootFile=import-local.prop- The initial properties file to read. This file can include other files, which must also be in the class path.
- It is also possible to specify or override many tailer settings by include other -D entries instead of writing them into the properties file.
-Dworkspace="C:\Program Files\WindowsTailer\workspaces"- The working directory for the process.
- The tailer will expect to find a writable logs directory as a peer of the workspace path.
-Ddevroot="C:\Program Files\WindowsTailer\java_lib"- Path to the Iris binaries (JARs).
- Same as the first half of the class path in this example.
-Dprocess.name=tailer- The process name for this process.
-Dlogging.processes=[comma-separated list]- Process names to be found in the tailer config XML files.
-Dintraday.tailerID=1- ID for the tailer process that must match tailer instance specific properties from the properties file.
-
com.illumon.iris.logtailer.LogtailerMain- The class to run.
Other properties that could be included, but are often set in the properties file instead:
-Ddata.import.server.[friendly_name].host=[host_name or ip_address]
-Ddata.import.server.port=22021
-Dlog.tailer.enabled.1=true
-Dlog.tailer.1.defaultDestinations=[friendly_name]
-Dlog.tailer.configs=tailerConfig.xml
-DpidFileDirectory=c:/temp/run/illumon
Note that friendly_name can be pretty much anything; the tailer process is just expecting to find a data.import.server.[friendly_name].host entry that matches the name specified for defaultDestinations.
Also, if logging to the console is desired (e.g., when first configuring the process, or troubleshooting), -DLoggerFactory.teeOutput=true will enable log messages to be teed to both the process log file and the console.
Note: This should not be set to true in a production environment. It will severely impact memory usage and performance.
Automating Execution of the Tailer
There are several options to automate execution of the LogTailerMain process. Two possibilities are the Windows Task Scheduler or adding the process as a Windows Service.
The Task Scheduler is a Windows feature, and can be used to automatically start, stop, and restart tasks. Previous versions of the tailer process needed to be restarted each day, but current versions can be left running continuously.
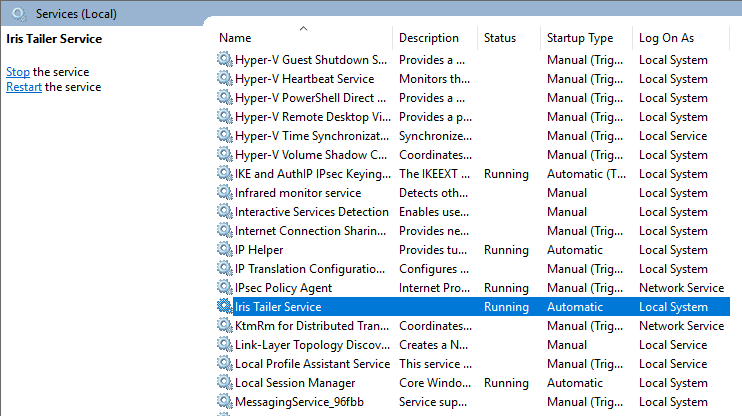
An easy way to configure the launch command to run as a Windows Service is to use NSSM (The Non-Sucking Service Manager). This free tool initially uses a command line to create a new service:
nssm install "service_name"
The tool will then launch a UI to allow the user to browse to the file to be executed as a service (e.g., runTailer.cmd, in this example), and to specify other options like a description for the service, startup type, and the account under which the service should run. Once completed, this will allow the tailer to be run and managed like any other Windows service.
Tailer Quick Start Guide
The following is a quick start guide to setting up a simple new tailer that looks for one table. The tailer will be called cus1, and use a configuration file called iris-customer-tailer.prop to send data to a local Data Import Server. In many cases, the default configuration will automatically find all files and no extra configuration is necessary. In this example, binary logs in the standard format are being created in a specific, non-standard directory.
1. Edit the host configuration file, and add an entry for the new tailer.
sudo vi /etc/sysconfig/illumon.confs/illumon.iris.hostconfig
The new entry should be in the existing
tailer)block, as another entry in the$proc_suffixcase contain the following lines.
tailer)
case "$proc_suffix" in
1)
CONFIGFILE=iris-tailer1.prop
PROCESSES="db_query_server,iris_controller,db_acl_write_server,authentication_server"
;;
Customer1)
CONFIGFILE=iris-tailer-Customer1.prop
PROCESSES="customer_app"
;;
esac
EXTRA_ARGS=""
RUN_AS=irisadmin
WORKSPACE=/db/TempFiles/$RUN_AS/$proc$proc_suffix
;;2. Add a monit entry for the new tailer.
sudo -u irisadmin vi /etc/sysconfig/illumon.d/monit/Customer1.conf
The new file should have the following data:
check process tailerCustomer1 with pidfile /var/run/illumon/tailerCustomer1.pid
start program = "/etc/init.d/iris start tailer Customer1"
stop program = "/etc/init.d/iris stop tailer Customer1"3. Create a property file for the new tailer. If the DIS isn't running locally, adjust the host property appropriately.
sudo -u irisadmin vi /etc/sysconfig/illumon.d/resources/iris-tailer-Customer1.prop
The file should have the following properties; these should go in a file in the tailer's classpath. Unless the directory is changed through the
log.tailer.defaultDirectoryproperty or the directory attribute, the tailer will look for log files in its<workspace>/../logsdirectory.
includefiles=iris-defaults.prop,IRIS-CONFIG.prop
log.tailer.enabled.Customer1=true
data.import.server.destination1.host=localhost
data.import.server.port=22021
log.tailer.configs=tailerConfigCustomer1.xml4. Create the tailer's XML file to specify the log(s) to tail.
sudo -u irisadmin vi /etc/sysconfig/illumon.d/resources/tailerConfigCustomer1.xml
The file should have the following details. Adjust the values of the tableName and namespace attributes so that they contain the appropriate values.
<Processes>
<Process name="customer_app">
<Log fileManager="com.illumon.iris.logfilemanager.StandardBinaryLogFileManager"
tableName="CustomerTable"
namespace="CustomerNamespace"
</Process>
</Processes>Note: Without specifying
logDirectoryin the .xml ordefaultDirectoriesin the .prop file, it will search for .bin files in/db/TempFiles/irisadmin/logs.5. Ensure that monit reloads its configuration so it can see the new tailer.
sudo monit reload
6. If it hasn't started with the monit reload, start the new tailer now.
sudo monit start tailerCustomer1
The tailer should start and create its own logs, indicating that it's finding and tailing the appropriate binary log files.
Last Updated: 23 September 2019 12:17 -04:00 UTC Deephaven v.1.20181212 (See other versions)
Deephaven Documentation Copyright 2016-2019 Deephaven Data Labs, LLC All Rights Reserved