Integrating Python with Deephaven
Python can be used in the Deephaven Console or in the scripts used within persistent queries. Python clients can also be used to perform remote queries.
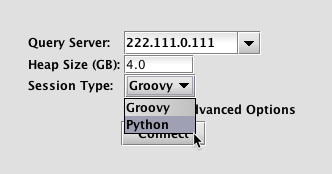
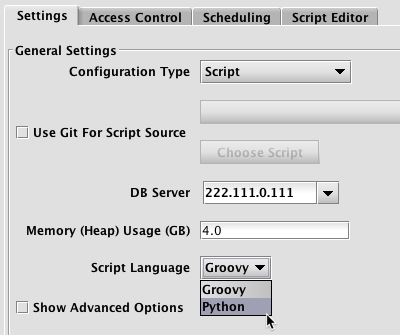
When a user launches a console or creates scripts for a persistent query, they will be prompted to choose between Groovy and Python.
|
When launching a Deephaven Console |
In the Persistent Query Configuration Editor |
|
|
Depending on whether you want to run Python within or outside of the Deephaven console, different Python-related packages will need to be installed. See below:
Installing Deephaven Python Packages on the Server
To integrate Python with Deephaven, the following server installations are required for all users.
Python v2.7.9
Python v2.7.9 or greater can be downloaded from https://www.python.org/
(Note: Python 3.x is not yet supported.)
Deephaven-specific Python Packages
deephaven-jpy is used to translate between Java and Python, and must be installed on the Deephaven Query server. Users can then use Python in the Deephaven Console without needing to install any other related Python packages on the client as the Deephaven Console sends the Python code to the Query Server to be executed. deephaven-jpy is packaged in .whl format for Linux x86_64 platforms, and can be downloaded from GitHub at: https://github.com/illumon-public/illumon-jpy/releases.
Ensure JDK_HOME is set and is added to your PATH. For example:
export JDK_HOME=/usr/java/latest
export PATH=$PATH:$JDK_HOME/bin
To install, unpack the release and install the .whl file with pip using the following:
tar xzf deephaven-jpy-*.tar.gz
sudo pip install deephaven_jpy*.whl
Installing Deephaven Python Packages on Client Workstations
The following client installations are required if you plan to execute Python queries outside of the Deephaven Console.
Python v2.7.9
Python v2.7.9 or greater can be downloaded from https://www.python.org/.
(Note: Python 3.x is not yet supported.)
Deephaven-specific Python Packages
Both deephaven-jpy and deephaven - a package required to run Python queries outside of the console - need to be installed on client workstations. See specific instructions below:
For Windows 64-bit Workstations
Ensure JDK_HOME is set and is added to your PATH. For example:
set JDK_HOME=C:\Program Files\Java\jdk1.8.0_162
set PATH=%JDK_HOME%\bin;%JDK_HOME%\jre\bin\server;%PATH%
Both deephaven-jpy and deephaven can be installed by running the following command:
pip install deephaven
For Mac OS X (v10.12) Workstations
Ensure JDK_HOME is set and is added to your PATH. For example:
export JDK_HOME=$(/usr/libexec/java_home)
export PATH=$PATH:$JDK_HOME/bin
Both deephaven-jpy and deephaven can be installed by running the following command:
pip install deephaven
Note: If you have an older installation of deephaven-jpy, you should update the JDK path used by deephaven-jpy by running the following:
python -m jpyutil
For Linux-based Workstations
Both deephaven-jpy and deephaven need to be installed on Linux-based Workstations. The installation instructions are identical to those used when installing on the server.
Ensure JDK_HOME is set and is added to your PATH. For example:
export JDK_HOME=/usr/java/latest
export PATH=$PATH:$JDK_HOME/bin
deephaven-jpy is packaged in .whl format for Linux x86_64 platforms, and can be downloaded from GitHub at: https://github.com/illumon-public/illumon-jpy/releases. To install, unpack the release and install the .whl file with pip using the following:
tar xzf illumon-jpy-*.tar.gz"
sudo pip install deephaven_jpy*.whl
deephaven can be installed by running the following command:
pip install deephaven
Note: If you have an older installation of deephaven-jpy, you should update the JDK path used by deephaven-jpy by running the following:
python -m jpyutil
For Other Platforms
For other client platforms, such as Windows 32-bit, deephaven-jpy must be built from source using the jpy build instructions on GitHub.com at https://github.com/illumon-public/illumon-jpy.
Testing the Python Server Installation
To test the Python installation, open a Deephaven console. To the right of Session Type, click the drop-down list and select Python as shown below. Then click Connect.
Once the console has connected to the server, paste the following into the console window and then press Enter on your keyboard:
def foo(x):
return x**2
z=3.1415
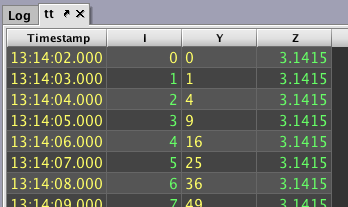
tt=db.timeTable("00:00:01").update("I=i", "Y=foo.call(i)", "Z=z")
If the following table appears in the lower portion of the console window, Python is ready to use in the Deephaven console.
Testing the Python Client Installation
The testiris.txt script has an example of creating a remote query client; remote database, and executing remote queries.
Note: On a Mac, you may need to install a JDK 6 to launch the integration even though you must actually be running JDK 8. See: https://github.com/s-u/rJava/issues/37.
Python Usage Examples
Python Variables and Functions in Your Query Scope
You can use the import command to export an arbitrary Python object to your global query scope. For example, the following exports the math object:
import math
The math object is brought into your workspace and query language constructs will interpret it as a PyObject wrapper. Thus, if you were to write a formula like the following, the engine will not be able to identify the pow field inside the PyObject wrapper:
tt=db.timeTable("00:00:01").update("Y=math.pow.call(2, i)")
Instead, you should use a statement like the following:
from math import pow
tt=db.timeTable("00:00:01").update("Y=pow.call(2, i)")
Default Python Imports for Workers
You can set the python.default.imports property to a text file to run imports at the beginning of each python worker session. Note: this assumes a default configuration, where core/illumon_jpy_init.py is run when initializing a worker. For example:
-Dpython.default.imports=/usr/illumon/latest/etc/importpython.txt
In this example, importpython.txt has the following import statements:
from math import pow
from illumon.iris.TableTools import emptyTable
The pow and emptyTable functions become available immediately upon opening a Python Iris Console or Persistent Query. Commands in this file that are not import statements will not be run.
It is also possible to specify default Java imports. For example:
-Dpython.default.javaclass.imports=/usr/illumon/latest/etc/importjava.txt
In this example, importjava.txt has the following fully qualified Java paths, separated one per line
java.lang.String
java.lang.Math
Python to Java Optimizations
It is also worthwhile to note that each formula application against a Python variable will require traversing the translation layer. For large data, it is best to minimize language transitions to achieve the best possible performance. For example, if you have a Python List, it is possible to use the .contains method within your query string as shown below:
symList = ["AAPL","GOOG"]
t = db.t("LearnIris","StockTrades").where("Date=`2017-08-22`")
filteredT = t.where("symList.contains(Sym)")
However, to evaluate this condition filter, the Java to Python boundary must be crossed on each row of your data. Although the script is in Python and the symList object is a Python object, the Deephaven query engine ultimately evaluates formulas as Java objects and expressions. As the translation between Java and Python (or vice versa) can be expensive, you should seek to minimize the transitions between languages for large data sets. In this case, we can convert our Python list to a Java object before applying the filter, as shown below:
hashSet = jpy.get_type("java.util.HashSet")
hs = hashSet()
for sym in symList:
hs.add(sym)
filteredT = t.where("hs.contains(Sym)")
The hs.add(sym) call requires a Python to Java call, but it is only performed once for each element in symList. The hs object is a native Java type; and no language translation needs to be performed while evaluating the condition filter for each row of the data. When operating on large data sets, it is important to be mindful of language transitions, and when possible recast your filters (where) or formulas (select, update, view, updateView) to minimize them whenever possible.
This filter is actually a special case, in that instead of writing it as a condition filter; it can be written as a match filter. When possible, you should convert your formula to a match filter, which Deephaven can interpret without any language translations, and potentially apply other optimizations. For example:
filteredT = t.where("Sym in symList")
pandas DataFrame Integration
Deephaven's Python integration includes built-in methods to convert pandas DataFrames to tables and tables to pandas DataFrames. These methods are available upon starting up a Deephaven Python Console via illumon_jpy_init.py, the default console initialization script.
table_to_df
The table_to_df method takes a table and copies its data into a pandas DataFrame. If the table is ticking, a snapshot will be taken before copying the data.
For example:
t = db.t("LearnIris", "StockTrades").where("Date = `2017-08-25`", "USym = `AAPL`")
df = table_to_df(t)
The method header syntax follows:
def table_to_df(table,convert_nulls = False,categoricals=None):
There are two optional parameters:
- Pandas does not currently support null-types in integer or boolean type columns.
convert_nullsspecifies whether to convert Deephaven columns of these types (which do support nulls) into types that pandas columns do support (float and object). Ifconvert_nullsis false, the type will be preserved but in the resulting dataframe integer null values will be represented as<integertype>.MIN_VALUEand boolean null values as false. categoricalsis a list of columns to convert to categoricals in the DataFrames. This may improve performance in certain cases. See: https://pandas.pydata.org/pandas-docs/stable/categorical.html
df_to_table
The df_to_table method takes a pandas DataFrame and copies its data into a table.
For example:
import pandas as pd
import numpy as np
d = {'col1': [1, 2], 'col2': [3, 4]}
df = pd.DataFrame(data=d, dtype=np.int8)
t = df_to_table(df)
Note: Integers of type uint64 are converted to a String, as Java does not support that type. Currently, DataFrame columns containing iterables are only supported if the iterables are of uniform type and are one-dimensional. Otherwise a TypeError will be thrown.
Global Deephaven Imports
The Deephaven Python environment imports some common Deephaven types from Java into Python. The following types can be imported from under the illumon.iris namespace; e.g., import illumon.iris.Calendars.
Remote queries and workers:
- Calendars
- DBTimeUtils
- TableTools
- TableManagementTools
- QueryScope
Only from remote queries:
- RemoteQueryClient
Only from workers:
- plot
You may use jpy.get_type to add additional Java types (either from the Deephaven package or any other package) to your Python namespace.
Run help("iris") or run help on a specific module, e.g., help("iris.TableTools") to see more documentation and a list of functions and packages available in each module. For example, to import the TableTools package, run the following:
from iris import TableTools
To import all packages at once run the following:
from iris import *
You can use then use the Table Tools package as you would in a standard Groovy console. For example:
T = TableTools.emptyTable(100).updateView("Col1 = `A`")
To import additional Java classes, you may use importjava("fully.qualified.class.path"). For example:
importjava("java.lang.String")
Hello = String("Hello world!")
Size = Hello.length()
Conversely, importstatic("fully.qualified.class.path") will import static members from a Java class to the Python namespace. For example:
importstatic("java.lang.Integer")
intFive = valueOf("5")
When the same method name exists in a class that was previously imported and in a new one that is being imported, the new import will take the place of the older import. For example, the following will use Integer.valueOf() when evaluating "5" (both java.lang.Integer and java.lang.String have valueOf methods.)
importstatic("java.lang.String")
importstatic("java.lang.Integer")
intFive = valueOf("5")
You may find it useful to use Java arrays instead of a similar Python structure such as a list. A common example is when you receive a "Too many matching overloads found" error message when calling a Java method.
The following can be used to create a Java array with a given type:
java_array(type, values)
For primitive arrays, the type argument is just the name of the primitive (e.g., int, double, etc). For arrays of Java objects, the fully qualified class path is required. Values can be a Python sequence such as a list or memory buffers like a NumPy array. For example:
java_array('int', [1,2,3])
java_array('java.lang.String', ["Deephaven", "Rocks!"])
Convenience methods exist for the primitive arrays:
IntArray(values)DoubleArray(values)FloatArray(values)LongArray(values)ShortArray(values)BooleanArray(values)ByteArray(values)
Currently-loaded static methods can be viewed by running: print dir()
Another nuance to be aware of is how jpy handles resolution of overloaded methods. Effectively, when a call is made to something like valueOf(1), jpy will iterate through the instances of valueOf() and pick the first one where 1 can be implicitly assigned to its input type. This may mean that the instance used is valueOf(int) or valueOf(boolean) or even valueOf(char). This is true even if the passed value is a typed variable rather than a constant expression - i.e., valueOf(int) may still be mapped to valueOf(char). In cases where such ambiguity of method mapping is a concern, it may be necessary to write uniquely named wrapper methods, such as:
public static String valueOfBoolean(boolean val) {
return String.valueOf(val);
}
This moves the overloaded method resolution to Java, ensuring that val is preserved as a boolean and passed to String.valueOf(boolean).
Default Classpaths
The start_jvm.py script sets up default Deephaven Python integration including default classpaths. These are appended to any user classpath information provided by the jvm_classpath argument.
For client systems, the default classpath includes (under devroot):
private_classesprivate_jarsoverrideresourceshotfixesjava_lib
For servers it includes:
etcunderworkspace/etc/sysconfig/illumon.d/override/etc/sysconfig/illumon.d/resources/etc/sysconfig/illumon.d/java_lib/*/etc/sysconfig/illumon.d/hotfixes/*etcunderdevrootjava_libunderdevroot
Possible Errors
ImportError: libjvm.so: cannot open shared object file: No such file or directory
ImportError: jvm.dll: cannot open shared object file: No such file or directory
On Linux/Mac: if you get the previous error, you'll need to set the environment variable
LD_LIBRARY_PATHto the location of the filelibjv.soOn Windows: set the
LD_LIBRARY_PATHto the location of the filejvm.dllOn both systems, the file will be found in the
/server/ folderof your JDK location. For example, on a Linux system, the path would be/usr/java/jdk1.8.0_162/jre/lib/amd64/server/
-ImportError: No module named iris
The
illumonandirismodules must be placed on the Python path before they can be used. This can be done via the following Python code:import sys
sys.path.append("/usr/illumon/latest/python/illumon")
import irisThis code will work for the lifetime of the interpreter. If you want to make this permanent, you will need to append to the
PYTHONPATHenvironment variable.
Last Updated: 23 September 2019 12:17 -04:00 UTC Deephaven v.1.20181212 (See other versions)
Deephaven Documentation Copyright 2016-2019 Deephaven Data Labs, LLC All Rights Reserved